Testing Normality in SPSS
You have set the methodological stage, entered your data, and you are getting ready to run those fancy analyses you have been anticipating (or dreading) all this time. If you have already read our overview on some of SPSS’s data cleaning and management procedures, you should be ready to get started. But wait! You are using a parametric analysis, and you know that stats book you read said something about normality. It is important, but what is it, and how do you know if your data follows normality? Well, first it is important to know what kind of normality you are looking for. There are two main types: univariate and multivariate.
Here we will talk about univariate normality. This goes along with the concept of the bell curve, which is the depiction of data with a lot of “middle-ground” scores, but only a few high or low scores. This follows the figure here, where the vertical (y) axis represents the number of people (or observations) with low, average, and high scores.
Need help conducting your analysis? Leverage our 30+ years of experience and low-cost same-day service to complete your results today!
Schedule now using the calendar below.
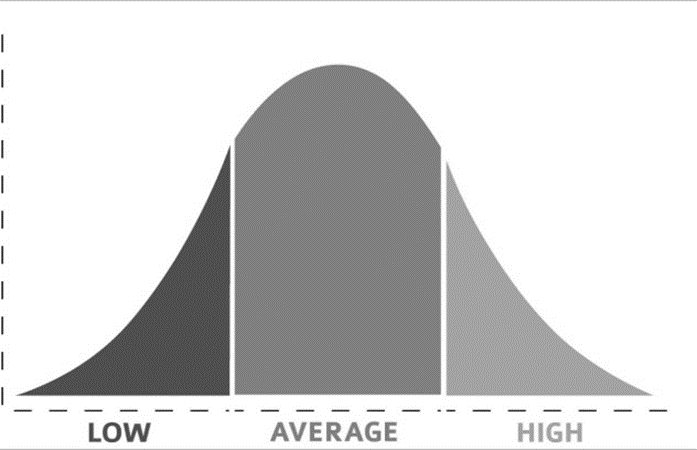
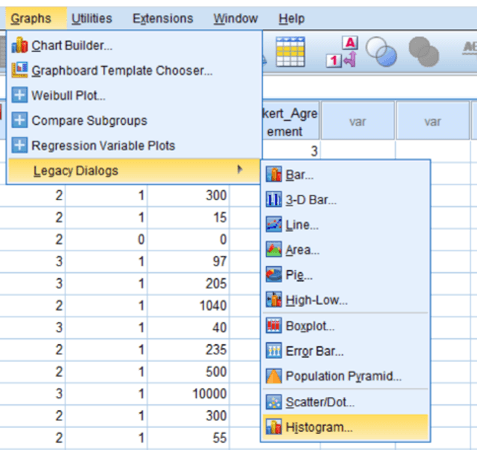
A few deviations from this distribution can exist. For example, shifting the hump to one side creates skew. A high skew can mean there are disproportionate numbers of high or low scores. On the other hand, platykurtosis and leptokurtosis happen when the hump is either too flat or too tall (respectively). In SPSS, go to Graphs > Legacy Dialogs > Histogram and select your variable. Clicking OK should show you a chart that looks similar to the one above. If your distribution does not follow a typical bell shape, you might need to dig into the numbers.
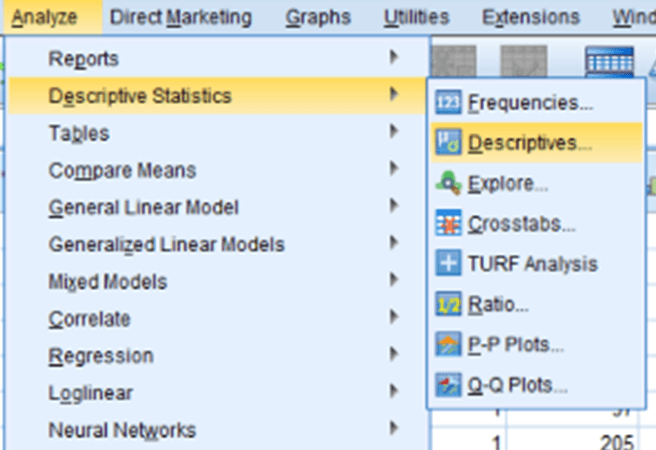
To get skew and kurtosis values in SPSS, go to Analyze > Descriptive Statistics > Descriptives and select your variables. Clicking on Options… gives you the ability to select Kurtosis and Skewness in the options menu. Click OK and check for Skew values over 2 or under -2 and Kurtosis values over 7 or under -7. Those values might indicate that a variable may be non-normal.
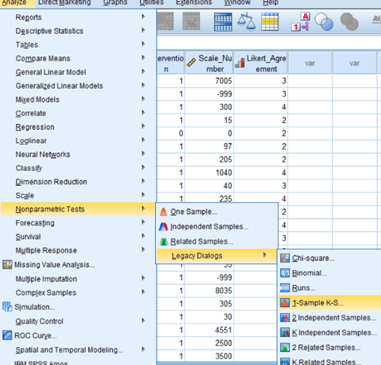
With all that said, there is another simple way to check normality: the Kolmogorov Smirnov, or KS test. This test checks the variable’s distribution against a perfect model of normality and tells you if the two distributions are different. You can reach this test by selecting Analyze > Nonparametric Tests > Legacy Dialogs > and clicking 1-sample KS test. Just make sure that the box for “Normal” is checked under distribution.
Check the difference from a normal distribution using a p-value, interpreted like any other. A p-value < 0.05 means a significant difference from normality, which may be a concern. A p-value ≥ 0.05 means no significant difference, so normality-dependent analysis can proceed.