One Sample T-Test
The one sample t-test is a statistical procedure used to determine whether a sample of observations could have been generated by a process with a specific mean. Suppose you are interested in determining whether an assembly line produces laptop computers that weigh five pounds. To test this hypothesis, you could collect a sample of laptop computers from the assembly line, measure their weights, and compare the sample with a value of five using a one-sample t-test.
Hypotheses
There are two kinds of hypotheses for a one sample t-test, the null hypothesis and the alternative hypothesis. The alternative hypothesis assumes that some difference exists between the true mean (μ) and the comparison value (m0), whereas the null hypothesis assumes that no difference exists. The purpose of the one sample t-test is to determine if the null hypothesis should be rejected, given the sample data. The alternative hypothesis can assume one of three forms depending on the question being asked. If the goal is to measure any difference, regardless of direction, a two-tailed hypothesis is used. If the direction of the difference between the sample mean and the comparison value matters, either an upper-tailed or lower-tailed hypothesis is used. The null hypothesis remains the same for each type of one sample t-test. The hypotheses are formally defined below:
• The null hypothesis (\(H_0\)) assumes that the difference between the true mean (\(\mu\)) and the comparison value (\(m_0\)) is equal to zero.
- • The two-tailed alternative hypothesis (\(H_1\)) assumes that the difference between the true mean (\(\mu\)) and the comparison value (\(m_0\)) is not equal to zero.
- • The upper-tailed alternative hypothesis (\(H_1\)) assumes that the true mean (\(\mu\)) of the sample is greater than the comparison value (\(m_0\)).
- • The lower-tailed alternative hypothesis (\(H_1\)) assumes that the true mean (\(\mu\)) of the sample is less than the comparison value (\(m_0\)).
of a sample of laptops is equal to five pounds, the real question being asked is whether the process that produced those laptops has a mean of five.
Need help conducting your One Sample T-Test? Leverage our 30+ years of experience and low-cost same-day service to complete your results today!
Schedule now using the calendar below.
The mathematical representations of the null and alternative hypotheses are defined below:
- \(H_0:\ \mu\ =\ m_0\)
- \(H_1:\ \mu\ \ne\ m_0\) (two-tailed)
- \(H_1:\ \mu\ >\ m_0\) (upper-tailed)
- \(H_1:\ \mu\ <\ m_0\) (lower-tailed)
Note. It is important to remember that hypotheses are never about data, they are about the processes which produce the data. If you are interested in knowing whether the mean weight
Assumptions
As a parametric procedure (a procedure which estimates unknown parameters), the one sample t-test makes several assumptions. Though t-tests are robust, it’s good practice to check the degree of assumption deviation to assess result quality. The one sample t-test has four main assumptions:
- The dependent variable must be continuous (interval/ratio).
- The observations are independent of one another.
- The dependent variable should be approximately normally distributed.
- The dependent variable should not contain any outliers.
Level of Measurement
The one sample t-test requires the sample data to be numeric and continuous, as it is based on the normal distribution. Continuous data can take on any value within a range (income, height, weight, etc.). The opposite of continuous data is discrete data, which can only take on a few values (Low, Medium, High, etc.). Occasionally, discrete data can be used to approximate a continuous scale, such as with Likert-type scales.
Independence
Independence of observations is usually not testable, but can be reasonably assumed if the data collection process was random without replacement. In our example, we would want to select laptop computers at random, compared to using any systematic pattern. This ensures minimal risk of collecting a biased sample that would yield inaccurate results.
Normality
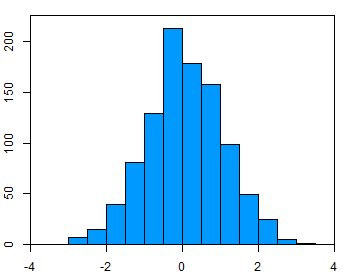
To test the assumption of normality, a variety of methods are available, but the simplest is to inspect the data visually using a histogram or a Q-Q scatterplot. Real-world data are rarely perfectly normal, so you can consider the assumption met if the shape is roughly symmetric and bell-shaped. The data in the example figure below is approximately normally distributed.
Outliers
An outlier is a data value which is too extreme to belong in the distribution of interest. Let’s suppose in our example that the assembly machine ran out of a particular component, resulting in a laptop that was assembled at a much lower weight. This is a condition that is outside of our question of interest, and therefore we can remove that observation prior to conducting the analysis. However, just because a value is extreme does not make it an outlier.
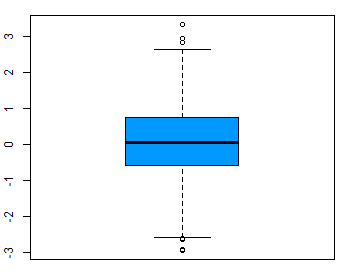
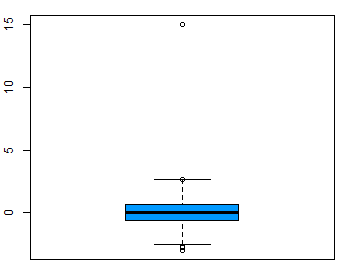
Let’s suppose that our laptop assembly machine occasionally produces laptops which weigh significantly more or less than five pounds, our target value. In this case, these extreme values are absolutely essential to the question we are asking and should not be removed. Box-plots are useful for visualizing the variability in a sample, as well as locating any outliers. The boxplot on the left shows a sample with no outliers. The boxplot on the right shows a sample with one outlier.
Procedure
The procedure for a one sample t-test can be summed up in four steps. The symbols to be used are defined below:
- \(Y\ =\ \)Random sample
- \(y_i\ =\ \)The \(i^{th}\) observation in \(Y\)
- \(n\ =\ \)The sample size
- \(m_0\ =\ \)The hypothesized value
- \(\overline{y}\ =\ \)The sample mean
- \(\hat{\sigma}\ =\ \)The sample standard deviation
- \(T\ =\)The critical value of a t-distribution with (\(n\ -\ 1\)) degrees of freedom
- \(t\ =\ \)The t-statistic (t-test statistic) for a one sample t-test
- \(p\ =\ \)The \(p\)-value (probability value) for the t-statistic.
The four steps are listed below:
- 1. Calculate the sample mean.
- \(\overline{y}\ =\ \frac{y_1\ +\ y_2\ +\ \cdots\ +\ y_n}{n}\)
- 2. Calculate the sample standard deviation.
- \(\hat{\sigma}\ =\ \sqrt{\frac{(y_1\ -\ \overline{y})^2\ +\ (y_2\ -\ \overline{y})^2\ +\ \cdots\ +\ (y_n\ -\ \overline{y})^2}{n\ -\ 1}}\)
- 3. Calculate the test statistic.
- \(t\ =\ \frac{\overline{y}\ -\ m_0}{\hat{\sigma}/\sqrt{n}}\)
- 4. Calculate the probability of observing the test statistic under the null hypothesis. This value is obtained by comparing t to a t-distribution with (\(n\ -\ 1\)) degrees of freedom. This can be done by looking up the value in a table, such as those found in many statistical textbooks, or with statistical software for more accurate results.
- \(p\ =\ 2\ \cdot\ Pr(T\ >\ |t|)\) (two-tailed)
- \(p\ =\ Pr(T\ >\ t)\) (upper-tailed)
- \(p\ =\ Pr(T\ <\ t)\) (lower-tailed)
Once the assumptions have been verified and the calculations are complete, all that remains is to determine whether the results provide sufficient evidence to reject the null hypothesis in favor of the alternative hypothesis.
Interpretation
There are two types of significance to consider when interpreting the results of a one sample t-test, statistical significance and practical significance.
Statistical Significance
Statistical significance is determined by looking at the p-value. The p-value gives the probability of observing the test results under the null hypothesis. The lower the p-value, the lower the probability of obtaining a result like the one that was observed if the null hypothesis was true. Thus, a low p-value indicates decreased support for the null hypothesis. However, the possibility that the null hypothesis is true and that we simply obtained a very rare result can never be ruled out completely. The cutoff value for determining statistical significance is ultimately decided on by the researcher, but usually a value of .05 or less is chosen. This corresponds to a 5% (or less) chance of obtaining a result like the one that was observed if the null hypothesis was true.
Practical Significance
Practical significance depends on the subject matter. In general, a result is practically significant if the size of the effect is large (or small) enough to be relevant to the research questions being investigated. It is not uncommon, especially with large sample sizes, to observe a result that is statistically significant but not practically significant. Returning to the example of laptop weights, an average difference of .002 pounds might be statistically significant. However, a difference this small is unlikely to be of any interest. In most cases, both practical and statistical significance are required to draw meaningful conclusions.