Data Separation
Data separation is an issue that can occur while trying to fit an ordinal or binary logistic regression model. Separation occurs when a predictor variable (or set of predictor variables) perfectly predict your outcome variable. This can occur when all observations of a particular predictor have the same outcome. This is illustrated in the small dataset below, with a dichotomous (or binary) outcome variable.
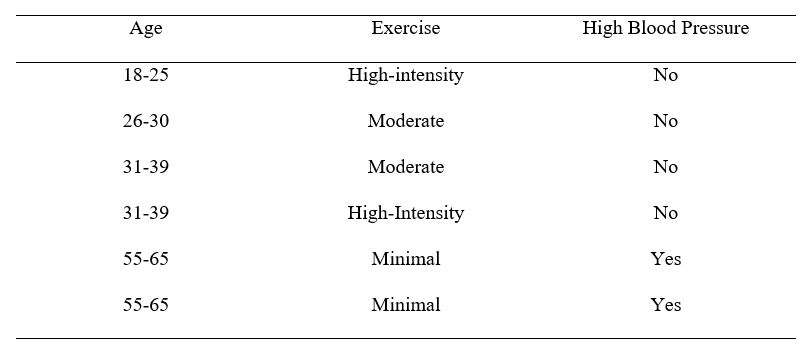
In the small dataset above, you can see that everyone who was in the outcome variable category of “No” had certain characteristics not shared with those in the outcome variable category of “Yes.” In other words, the age and exercise variables separate the outcome variable perfectly.

This can occur because particular subgroups may all have a particular outcome (in the example above, everyone who was aged 55-65 with minimal exercise had an outcome of high blood pressure). This may be because of an error made while coding data, or because you have a tiny sample size. For example, if our above dataset was expanded, we would probably see some 55-65 year old individuals who had the low blood pressure outcome.
Ok, so you have complete separation—that’s pretty interesting, right? You have seemingly found something that perfectly predicts your outcome! However, it is unlikely that this is actually the case, as there is not really such a thing as a perfect predictor in most real-world situations. Although we found in our extremely small sample above that every 55-65 year old who exercises minimally had low blood pressure, this certainly not the case in the population.
Statistically, when you have complete separation, the maximum likelihood estimate for the logistic regression analysis does not exist. In uncomplicated terms—your statistics software will not be able to compute the analysis and will give you a warning message. If you have partial separation, your parameter estimates will be biased. If you ever see ridiculously large coefficients in your results, you might want to investigate separation as a cause.
So, what can you do when you find separation in your data? Well, for starters, make sure you did not accidentally include a recoded version of your outcome in your predictors. You could remove the offending variable from your model, although this may not make sense depending on your research goals. Additionally, it may bias the estimates for other variables. You might be able to collapse certain categories (if it is reasonable to do so) so that there are more participants in a certain subcategory. For partial separation, you could do nothing and note that estimates for the variable causing the issue may be biased. Or, if you are able, you might be able to collect more data in the hopes that a larger dataset will have more variability.